We use the web for rich, complex interactions: to engage with one another, to make purchases or to do business, for creating and storing, and for numerous other use cases. And we think of all these interactions on the web today as decentralized interactions among peers, facilitated by transparent and secure services. In reality, powerful centralized services (able to manipulate, use, copy, and sell our data at will) mediate most of these transactions. Enter “Web3”.
Web3 is the evolution of the current Web2 internet infrastructure, based on the concepts of decentralization and self-sovereignty. But how Web3 can achieve these goals has been limited because the best tool we have for decentralization and self-sovereignty, the blockchain, only deals in tokens. And nearly all the blockchain-based applications today manipulate tokens in some way: trading, lending, locking, swaps, bridges, AMMs, auctions, NFTs. Businesses and people are more than financial applications; they run on data.
To facilitate the continued adoption of Web3, we’re making data accessible – not just files in a decentralized file store, but real data; rows and columns, keys and values – on the blockchain with our newest primitive.
Enabling Decentralized Data
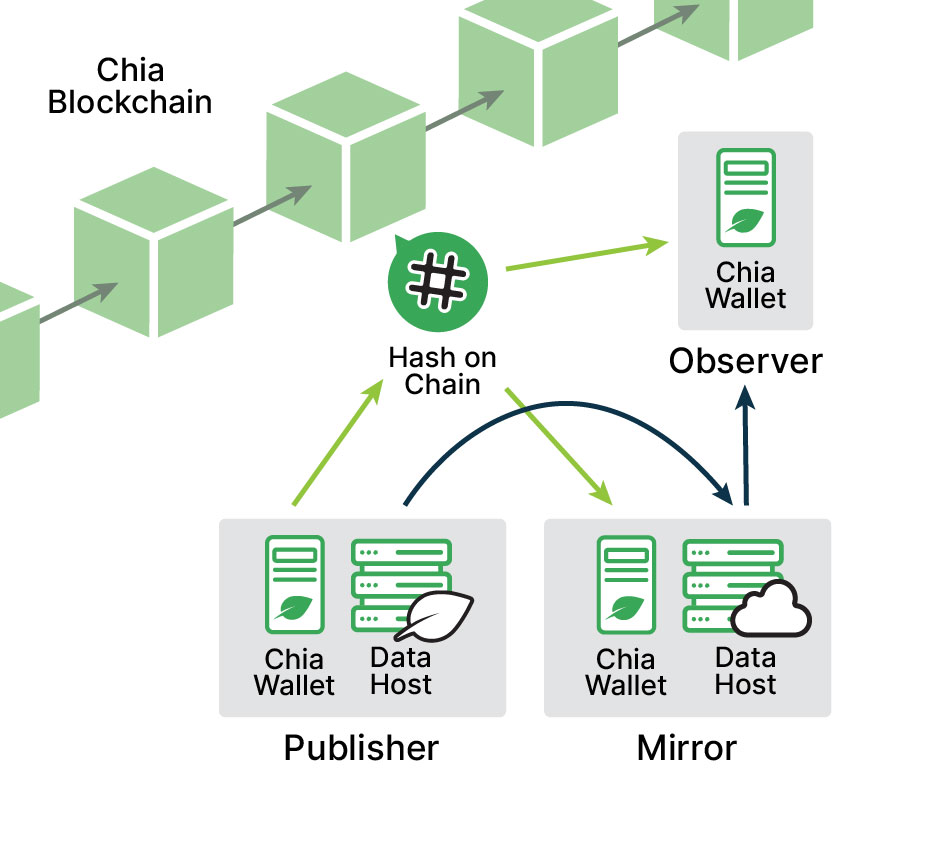
Introducing Chia DataLayer, a general-purpose decentralized database: anyone can publish tables of data, and others can subscribe to that data. The published data is as immutable as the Chia blockchain but not stored on the blockchain. Instead, proofs of the data are stored on the blockchain, along with URLs where someone can fetch the data. A subscriber can compare the received data to the proof on the blockchain and confirm that the data is correct.
Consider the simple example of a buyer and seller of a physical product: the buyer makes an offer for on-chain payment that directly references the description of the product and includes proof they’ve accepted the terms of service; the seller can only accept the payment by recording the requested receipt, including delivery address. That is a complete transaction on-chain. Compare this example to most crypto interactions where payments are devoid of context. There are many more applications for social networks, crowdfunding, event ticketing, gig economy, auditable data, etc – and many more ideas we haven’t begun to consider.
Download the new 1.6.0 release, check out the documentation, learn more below, and join us at our upcoming Q&A session.
Data: A Challenge and an Opportunity
From the beginning, we designed Chia’s blockchain using the coin set model, which, in addition to its financial use cases, allows any type of data to be stored. However, storing large amounts of data, and making frequent changes to said data, are not practical – a transaction block is only created every 52 seconds or so, and it has a maximum size of around 400 KB.
The blockchain doesn’t run faster or allow more data to be stored because Chia is committed to supporting low-end hardware such as the Raspberry Pi. Because of this commitment, Chia is the most decentralized blockchain in the world, with around 130,000 nodes. However, if you wanted to store something large on the blockchain, such as the complete works of Shakespeare, then all 130,000 Chia nodes would have to download and process the data. This would be – to put it mildly – inefficient.
But there is a better way to store large amounts of data by storing the data off-chain and using the blockchain to verify the data’s accuracy. That’s the gist of what the Chia DataLayer does.
What is Chia DataLayer: A Primer
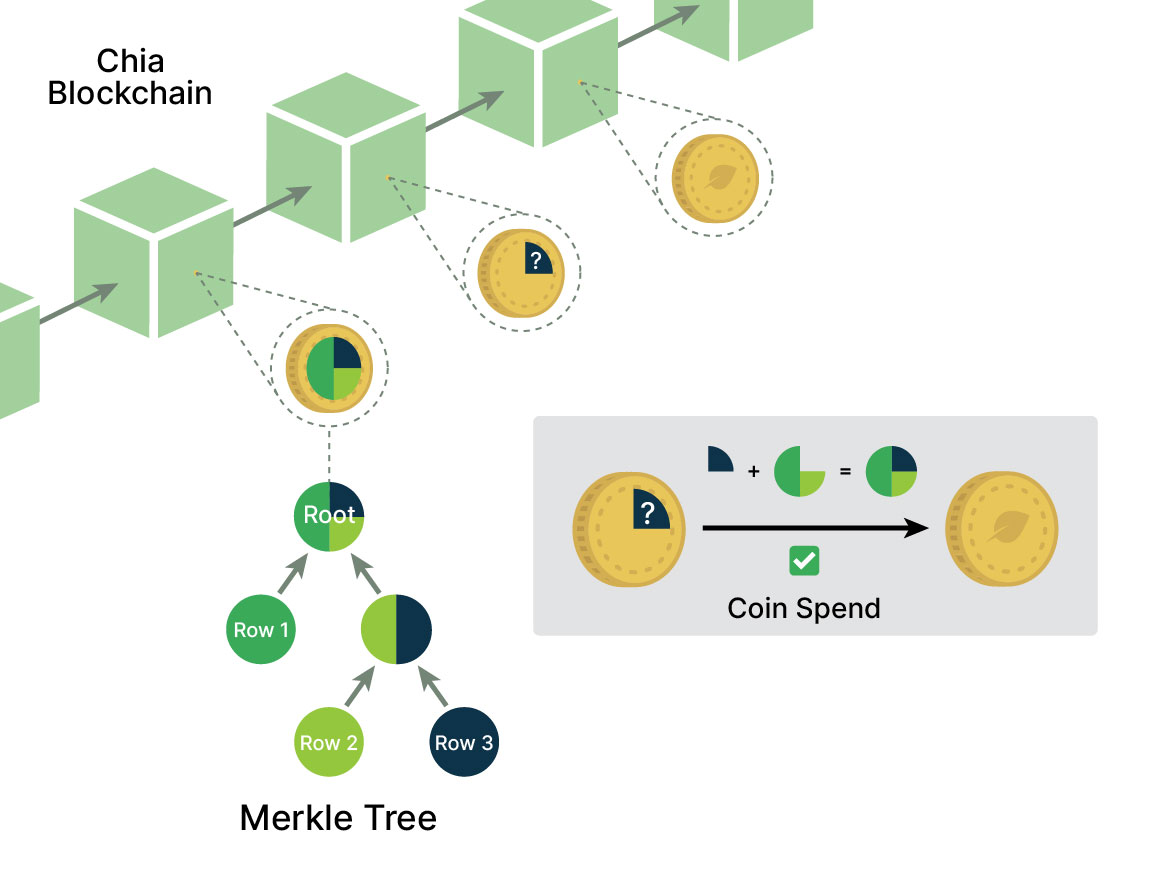
As a decentralized database, the Chia DataLayer allows users to store the original data locally. The hash of that data is then saved in a singleton (a coin with a unique ID that can be spent and recreated many times) with updated properties each time it is recreated. The on-chain component of Chia DataLayer is also a singleton. If the original data’s hash matches the hash stored on-chain, then the original data is guaranteed to be accurate.
At the basic level, the Chia DataLayer provides a shared data network with no central authority. Nodes in this network can subscribe to data from other nodes and receive updates whenever the data changes.
The real magic of DataLayer is the ability to use the data in smart contract transactions. Specifically, Chialisp code can directly process records stored in Chia DataLayer, opening up a new world of functionality for Chialisp programmers not available on any other blockchain.
A Real-World Example
The World Bank’s Climate Warehouse demonstrates a real-world use case of the Chia DataLayer. The Climate Warehouse, spearheaded by the World Bank, seeks to bring transparency and trust to the carbon markets. The World Bank developed several “simulations” of the Climate Warehouse, finally choosing the one developed on Chia, to refine a clear proposal for how it should work before handing it to an independent secretariat later this year.
Each participant in the Climate Warehouse publishes data in their DataLayer tables, using their Chia wallet and keys, running on its own infrastructure. For transparency, an observer node is accessible on the World Bank website, which subscribes to the data published by all the participants but does not publish any data. There is a “governance” node that publishes another DataLayer table with the list of DataLayer tables published by each of the recognized participants. Each participant and observer only needs to know the DataLayer table ID for the governance node to locate all of the other participants’ data.
The World Bank’s mission required blockchain technology for immutability and transparency. Adding another layer of complexity, the blockchain must also be sustainable, support their needs for storing data, and capable of running with minimal technical specifications. Chia is the only blockchain that met their requirements. The final simulation leveraging the Chia Blockchain has finished; more information on the project can be found here and access to a read-only “observer” node is available here.
Expanding Blockchain Capabilities through Chia DataLayer
We approached the opportunity space as a blue sky, understanding that blockchain technology and Web3 are still so new that many of the use cases haven’t yet been developed. That said, we built it with applicability and usability with today’s use cases and technology.
This isn’t another case of sprinkle blockchain on the problem – blockchain technology drives the key differentiation. A ledger with private write and public read access, with all transactions recorded on-chain creates total and novel transparency. Where we have for so long relied on trusting each organization in a federated database (Read: any industry-wide tracking of a product or process), we now have process controls and blockchain-enforced integrity.
We believe this to be a foundational technology that will forever change how we think about the scope of applications enabled through the immutability, transparency, and auditability of the Chia public blockchain.
Auditability: Using Chia DataLayer, subscribers can always review the immutable history of any changes made to data tables – allowing verifiable auditability. Every update creates a record to the blockchain (a hash or “mathematical proof”) which can be run against the database to ensure accuracy. Anyone can run the proof, which is a critical part of why a blockchain is, and should be, used in the first place.
Transparency: A Chia DataLayer table can only be updated by its owner, and all updates are visible and immutable on-chain. The provenance of any particular change is clear and unequivocal, and can be confirmed by any third party with access to read the data.
Durability and Accountability: Data in Chia DataLayer survives as long as there is any host serving a mirror of that data, whether provided by the original publisher of the data, or some other interested party. Even if the original publisher of data on Chia DataLayer chooses to stop serving the data, any other interested party can ensure that data survives by publishing a mirror.
Integrated: Chia DataLayer is a native part of Chia and provides unique capabilities that only an integrated solution could provide. Some solution providers offer databases periodically “pinned” to a blockchain for auditability, but these third-party solutions are not well-integrated to the underlying blockchain.
Sovereignty and Equality of Peers: All participants in a Chia DataLayer-based application are equal. No one entity can update another’s records, which creates a true, owner-sovereign way to store data. There is no central party hosting the data with the capability to censor or alter the data of other participants.
Functional: Chia DataLayer enables off-chain data to be proven on-chain and made available to Chialisp code so that it can become an active part of transactions.
We built Chia DataLayer as a solution to the challenges we’ve experienced in the ecosystem. It offers the expanded capabilities we believe will drive adoption of blockchain at scale, today and in the future.
The Path Forward
This release enables the intersection of data and blockchain technology. We’re only scratching the surface of what can be done with DataLayer. We understand this technology is coming early in the adoption cycle of blockchain as an infrastructure tool for most large organizations, and know that there are still use cases outside of what we can imagine yet to be developed. We’ve demonstrated the transparency use case, but expanded functionality is coming, including confidentiality and access control measures. While this release is important and includes the base functionality, we’re not done.
Included in this release of Chia DataLayer:
Proof Of Inclusion: The Chia DataLayer singleton can be spent by its owner in a way that cryptographically proves the inclusion of a particular row (or multiple rows), specified by the hash of the data in that row. Proofs of inclusion are the basis for accessing DataLayer data from Chialisp because once the data is proven, it can be used to drive other functionality, starting with the two-party commit, and moving beyond to include oracles and off-chain contracts.
Two-Party Commit: Using DataLayer offer files and proofs of inclusion, two people can coordinate a simultaneous (“atomic”) update of their respective data:
- Alice proposes an update, creating an offer file that includes proofs of inclusion of the added and changed rows she proposes to make in her own DataLayer tables and the rows she requests that Bob add or change in his tables.
- She saves the offer file and sends it to Bob.
- Bob opens the offer file and reviews the proposed changes to Alice’s DataLayer tables and the changes she requests of his DataLayer tables.
- If the changes are acceptable, Bob attaches an update to his DataLayer tables that includes at least the changes requested by Alice, and submits the completed offer to the blockchain.
- Both Alice’s and Bob’s DataLayer tables are simultaneously updated. If Bob had not completed the offer, neither table would be updated. Alice could have canceled the offer by updating her singleton, even if the update did not change the data.
Demonstrated through the lens of our previous example, the two-party commit feature enables two participants in the Climate Warehouse to coordinate an update between them to atomically record the transfer of records from one registry to another.
We will be providing further context on the features above, as well as details on our planned expansion to Chia Datalayer functionality in a follow-up post.
Releasing the Chia DataLayer into your hands is an exciting moment for us, made even more exciting by the prospect of seeing your entirely novel and imaginative use cases with the technology. We’re looking forward to the future you build!




